Objective: Gain access to digital assets (ie: pdf) for free and check how well PII data is protected for a given website
Disclaimer: I got permission to perform the tests and I did not downloaded any digital assets for free (PII and CC are sensitive)

I was regularly purchasing some digital assets (PDF reports) from a website and I was pleasantly surprised how well it was built, compared to similar websites. Being a security professional, I had the question: How secure, or how well is the report protected to prevent downloading without payment? I will emphasize that I did pay for the reports and asked for permission to do further security testing.
When testing the security of a website there is a blurred line between what’s considered public information or hacking. When you feel you are crossing the line, or you have doubts, it’s probably time to stop and ask for permission to investigate. If anyone has some good resource around this please share it with me!
Reconnaissance

As a first step, I usually try to understand what is powering the website in the back end. Often you will see it’s WordPress and you would look for some miss-configuration. However, a website with a proper budget will use a custom-built solution and these days GraphQL is very popular to power the back end API. I am not an expert in securing GraphQL, however, I saw many vulnerabilities arising from broken authorisation.

As it turns out this website is using GrapQL as well. Let’s explore.
Client-Side Data Manipulation
The website loads the report details from the client side by making a graphql request to fetch ProductPricing. Using burp we can manipulate the API response and change the cost of the report to 0. This will trick the front end and will allow us to go through the purchase process. It will not ask for CC details or any payment method given the report is considered free.
POST /graphql HTTP/1.1
Host: gateway.*****.com.au
{"operationName":"ProductPricing","variables":{"params":{"address_slug":The response will be changed to:
{"data":{"productPricing":{"product":{"id":29366,
"eta":"Available for download",
"cost":"0","discount":"0","second_charge":"450",

Well done team! ✅
The back end has verified the totals and detected the amounts are not correct and the purchase was canceled.
GraphQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
With GraphQL you can see what query the client is sending to the back end, but unless you know how the data is structured it is hard to come up with some meaningful queries to exfiltrate some data. Luckily GraphQL has an introspection system that will return information about the different data types, queries, and mutations.
|
|
It’s useful for an object to know what fields are available, so let’s ask the introspection system about Droid:
|
|
GraphQL Introspection
I was hoping the graphql server will return all the information that is available to the clients, however, this wasn’t that easy as I thought.
|
|
GraphQL introspection is not allowed by Apollo Server, but the query contained __schema or __type.
The development team was thoughtful enough and disabled introspection. Nice work! ✅
At this stage, I thought the graphql endpoint is a dead end. Without information about objects and the field names, it’s like groping in the dark.
Thinking outside the box
 It is common practice to have debugging features disabled in production and enabled in the staging or development environment. I tried to guess the name of the development graphql environment but I was unsuccessful in doing so. Using my experience playing CTF’s I remembered there are tools to discover subdomains by brute force or better yet by using some online tools. https://geekflare.com/find-subdomains/
It is common practice to have debugging features disabled in production and enabled in the staging or development environment. I tried to guess the name of the development graphql environment but I was unsuccessful in doing so. Using my experience playing CTF’s I remembered there are tools to discover subdomains by brute force or better yet by using some online tools. https://geekflare.com/find-subdomains/
Running some of the tools, but in particular, knockpy.py will reveal some common domain names (????.___.com.au):
-
- api
- autodiscover
- backyard.
- beta
- cdn.
- ci.
- dev
- gateway
- prod
- sip
- staging
- staging-backyard
- dev-backyard
- uat-gateway
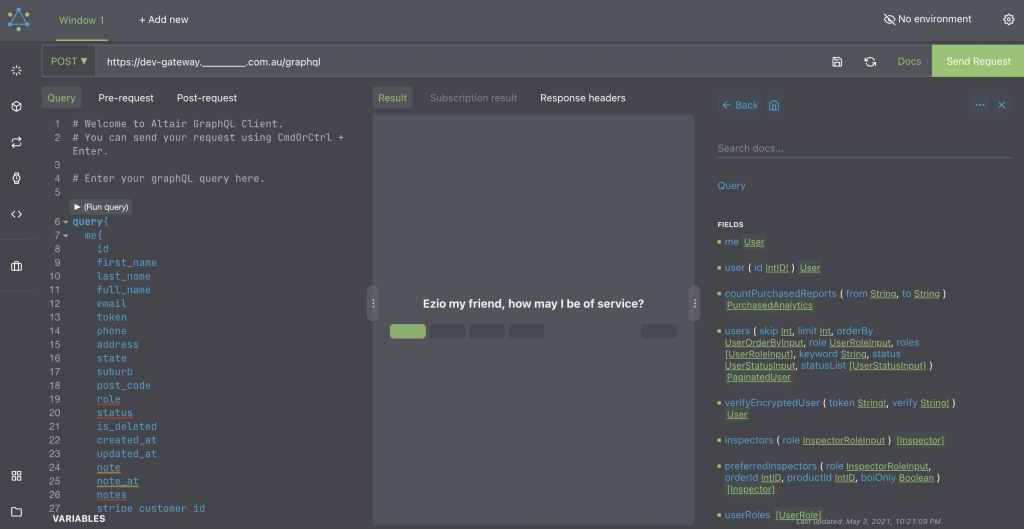
One caught my attention. dev.___.com.au. This subdomain is the development website and it was making requests to dev-gateway.___.com.au. 🥳 This was exciting but I needed to know if introspection is enabled or not. To do that I used a browser extension called Altair GraphGL Client.
This tool is nice because if introspection is enabled, using the interface, you can access the documentation, explore the objects, queries, and mutations.
I crossed my fingers 🤞 , entered the URL in the tool and magic 🧙♀️ happened! Introspection was enabled and I was able to construct queries and run them in production.
While this information is available it does not mean there is a vulnerability. It’s just easier to test.
After some research I found an interesting query productPricing.
{"operationName":"ProductPricing", ...
productPricing(params: $params) {
product {
id
eta
cost
discount
second_charge
is_second_charge_optional
eta_report_upload_datetime
...
}
...
}
}
}
"}All this information is displayed on the website, I haven’t learned anything in addition to what I already knew. However, at this stage, using the documentation available from the development site, I can expand this query in a meaningful way.
While innocent at first sight, the query includes information about the → Property. The property has → orders (this and the later information I leaner from the introspection system). And the orders have → purchaser information. (productPricing → Property → orders → purchaser.
The purchased object will have information such as name, address, email, phone, some stripe token id (this will be interesting later), CC last 4 digits, CC expiry date (lots’ of PII 😉).
{"data":{
"productPricing":{
"product":{"id":29366,"uuid":" danger dangerX-512d-4718-84b2-b28162b3c32e",
"orders":[{"id":102464,
"purchaser":{
"id":59744,
"stripe_card_token_id":"tok_********",
"first_name":"XYZ",
"last_name":"ABC",
"email":"****@gmail.com",
"post_code":"2000",
"credit_card_last_digit": 3214,
"credit_card_exp_year": 2022,
...Objective one achieved ✅
Gaining access to the report (for free, well kind of)
What happens when you are purchasing a report? The front end (using REACT) will make a call to the Stripe API, a POST request with all your credit card details, and some more. Stripe’s official JavaScript library records all browsing activity and reports it back to Stripe. This data includes:
-
- Every URL the user visits on my site, including pages that never display Stripe payment forms
- Telemetry about how the user moves their mouse cursor while browsing my site
- Unique identifiers that allow Stripe to correlate visitors to my site against other sites that accept payment via Stripe
This allows Stripe to detect any anomalies related to credit card fraud. Kudos to the team!
POST /v1/tokens HTTP/1.1
Host: api.stripe.com
card[name]=John Doe+Peter&card[number]=*************&card[cvc]=*****&card[exp_month]=08&card[exp_year]=55&
guid= dangerX-3a07-4f41-8015-c96452614cea26444f&muid= dangerXX-01bc-4d2b-b85b-76663d382c13e8c974&sid= dangerX-dede-4053-bd8f- danger danger&payment_user_agent=stripe.js%2Fbbe263476%3B+stripe-js-v3%2Fbbe263476&time_on_page=146801&referrer=https%3A%2F%2Fwww.________.com.au%2F&
key=pk_live_tMS8P5D7l danger danger dangerX&pasted_fields=numberpk_live_tMS8P5D7l danger danger dangerX is a public key to associate the request with a client. There is nothing sensitive about this.
Once Stripe validates the request it will create a credit card token object on their server and return a reference to this object. This way the client application will never see the credit card details and does not have to deal with securing the CC details and complying with PCI.
HTTP/1.1 200 OK
Server: nginx
{
"id": "tok_1Il danger dangerX",
"object": "token",
"card": {
"id": "card_1Iluv danger dangerX",
"object": "card",
....
"exp_month": 8,
"exp_year": 2055,
"funding": "credit",
"last4": "1234",
"name": "John Doe",
},
"livemode": true,
"type": "card",
"used": false
}The front end has access to this information and will instruct the back end to create the order and charge the credit card using the credit card object reference (tok_1Il danger dangerX)
POST /graphql HTTP/1.1
Host: gateway._____.com.au
{"operationName":"CreateOrder",
"variables":{"order":{"totalAmount":49,
"selectedUserType":"OO",
"customer":{"first_name":"Doe","last_name":"John",
"email":"******@yahoo.com","phone":"0410******",
.....
"stripe_customer_id":"",
"stripe_card_token_id":"tok_STRIPE_CARD_TOKEN_ID",
"credit_card_last_digit":"1234",
"credit_card_exp_month":"09",
"credit_card_exp_year":"2055",
....At this point, the download link will be sent via email.
Do you remember what information was available via graphql for a given product? What order information we were able to access? Well, everything from Stripe. My theory was that with this information you can instruct the backed to use the credit card object token to purchase a report but send it to a different email address. The side effect would be that the CC will be charged again by the back end.
I was permitted to test this theory, however, by the time I wanted the test the team implemented a fix and I wasn’t able to do so. Quite disappointing but much safer for the customers 😞
I still wanted to test if this would work and using my Stripe development account I was able to validate my theory.
curl https://api.stripe.com/v1/charges \
-u sk_test_51It5K7dsdfsdff: \
-d amount=2000 \
-d currency=aud \
-d source=tok_1It5XFHObXUk2FCy2Fhx2Tnlf \
-d description="Test Charge"As you can see the only information you need to change a CC is the stripe_card_token_id. The private key will be provided by the website in the back end. The website should not store any CC information other than the token id!
The combination of leaked personal information and credit card details is really bad. Luckily this was fixed in time before a malicious actor exploited this vulnerability. 🙂
Objective two achieved ✅ (although I did not receive the download link 🙂)
Key Learning
If you are using GraphQL make sure your objects are secured. Especially if you have queries that will return data from multiple objects.
Make sure you are exposing publicly just the fields your application needs to function properly. Just because some fields are not included in the original query, anyone can manipulate the query on the client-side to include additional fields.
The staging environment should not be exposed publicly, or if you have to, treat it like the production system. It should not have default credentials and it should not expose sensitive information. And do not use production data in staging.
If you do not need PII, do not store it. Simple as that. If you need to store any PII make sure to properly protect it and delete it once it’s not required anymore.





